"Nothing that I can do will change the structure of the universe." Einstein
Orthogonalization
Knowing what to tune in order to try to achieve one effect. This is a process we call orthogonalization. The different effects should be orthogonal to each other, meaning there should be NO interferences between different features.
Evaluation Metric
Single Number Evaluation Metric
= Average of P and R where P is Precision and R is Recall.
Precision is the % of correctly recognized entity out of % of entites in the set. Recall on the otherside is the % of actual entities of correctly recognized.
Satisficing And Optimizing Metric
Accuracy is has to be optimized and Running Time has to be satisfied.
False Positive is the parameter of recognizing an entity even if it is not.
Train/Dev/Test Distribution And Size
The distribution has a large impact on the project. The dev set is also called hold out cross validation set. Dev and test set should come from the same distribution.
Guideline
Choose a dev set and test set to reflect data you expect to get in the future and consider important to do well on.
Splitting Data
In the old days it has been normal to split data to 70% train and 30% test or 60% train, 20% dev and 20% test. But in modern times where we might have millions examples in our sets. Then it has become common to split into 98% train, 1%dev and 1% test set. The rule of thumb is to set our test set to be big enough to give high confidence in the overall performance of our system. There are possibilities where we don’t need a test set and we can split only into train/dev set. The purpose of the test set is to help us evaluate our final cost buys of the system.
Human-Level Performance
Human-Level Performance is a approximation to Bayes error. It helps to decide if Bias or Variance has to be optimized.
Reducing (Avoidable) Bias and Variance
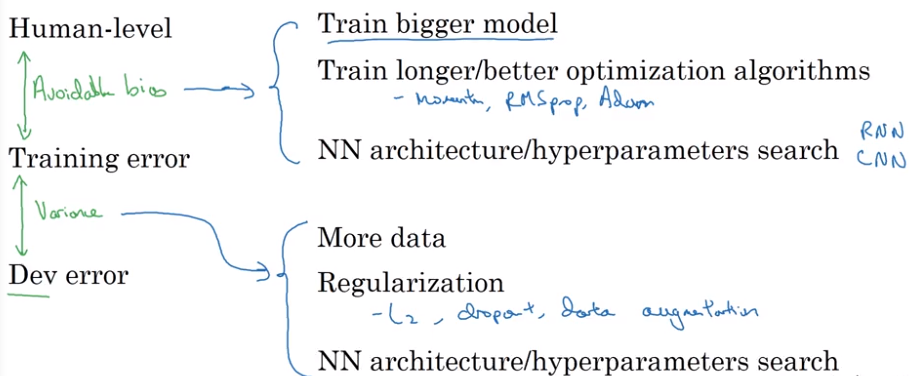
Approach
We should build our system quickly and the iterate over it.
Training And Testing On Different Distributions
More and more teams are using different data sets for training and testing ML algorithms. Mix the images from the different sources and shuffle it. Then take as usual a train/dev/test data from this dataset.
Bias And Variance With Mismatched Data Distributions
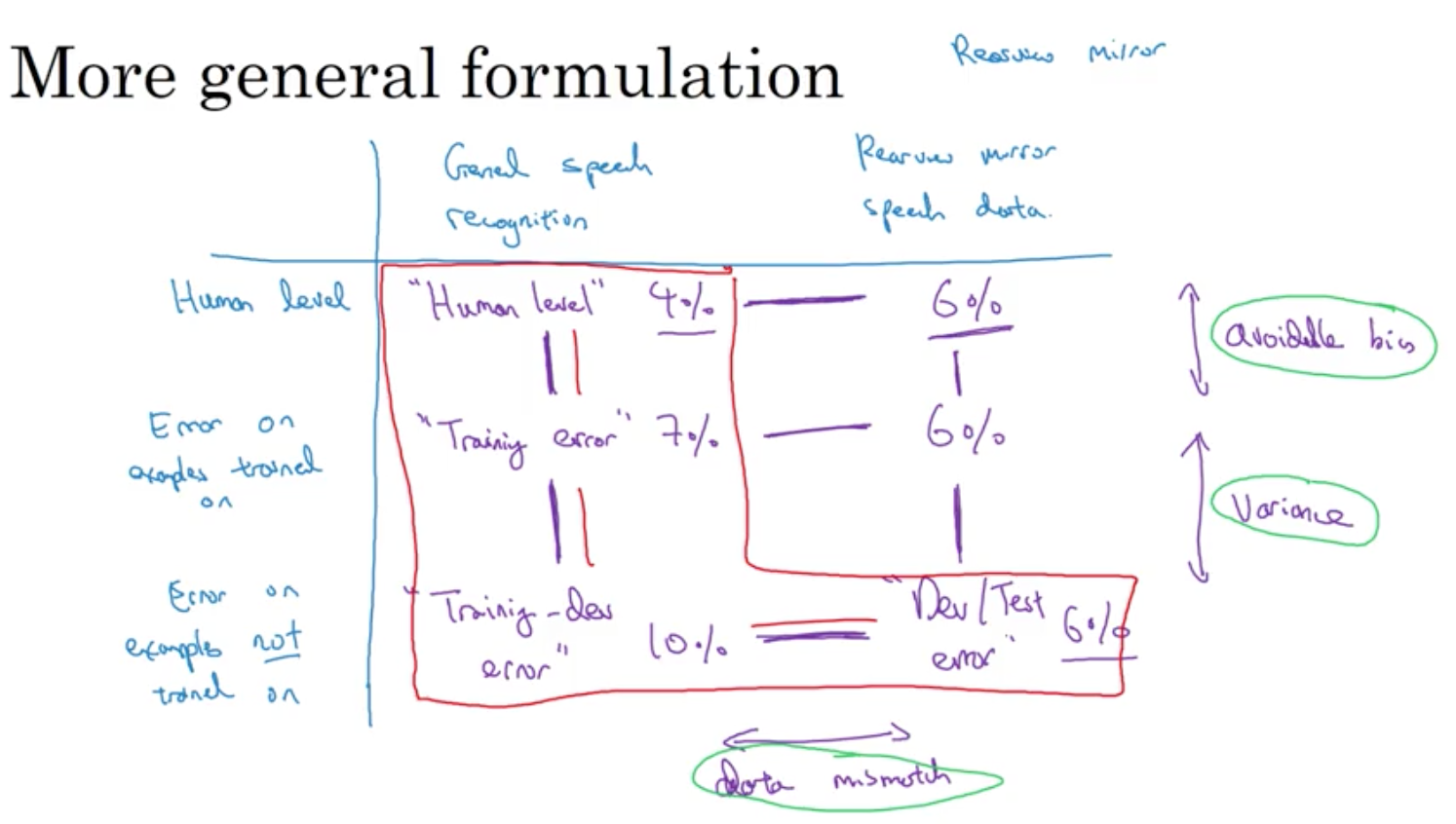
Cat Classifier Example
Assume humans get error
Training error …. 1%
Dev error …. 10%
Training-dev set: Same distribution as training set, but not used for training
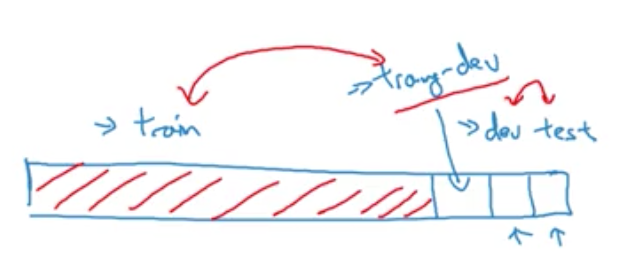
Training error …. 1% …. 1%
Training-dev error …. 9% …. 1.5%
Dev error …. 10% …. 10%
This tells us that we have a variance problem.
The second column is a second example and it shows a data mismatch problem.
Human error …. 0% …. 0%
Training error …. 10% …. 10%
Training-dev error …. 11% …. 11%
Dev errror …. 12% …. 20%
This example shows a bias problem and the second column shows a bias and a data mismatch problem.
Overall Sense

Addressing Data Mismatch
- Carry out manual error analysis to try to understand difference between training and dev/test sets, e.g. noisy car noise
- Make training data more similar or collect more data similar to dev/test set, e.g. simulate noise in data
Artificial Data Synthesis
For example: Add some noise to a recording speech to simulate an in-car audio. Let’s say we have 10,000 hours of recorded speech but only 1 hour of noise. If we now apply the same noise to every example, we will overfit to the car noise we added.
The challenge is normally for the human ear to recognize a repeating data to prevent overfitting.
Learning From Multiple Tasks
Transfer Learning
From Recognition To Radiology Diagnosis
If our new data set is small the rule of thumb is to retrain only the last layer of the neural network. In the case of a large new data set the rule of thumb is to retain the whole neural network.
From Speech Recognition To Triggerword Detection
We could retrain the whole neural network or only the last layer. We could also add new layers at the end to specify to the new goals.
When Transfer Learning Makes Sense
- Task A and B have the same input x
- We have a lot more data for task A than task B
- Low level features from A could be helpful for learning B
Multi-Task Learning
Start simultanously learning instead of sequential learning.
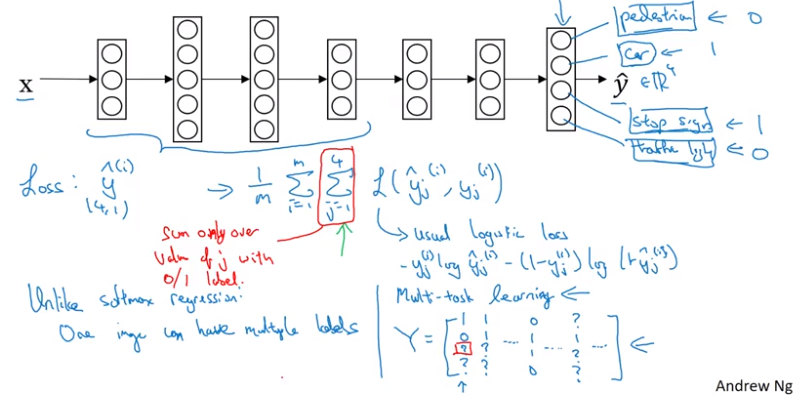
Simplified Autonomous Driving Example
Image recognition on an image:
Feature and appearance y
pedestrian 0
car 1
stop signals 1
traffic lights 1
When Multi-Task Learning Makes Sense
- Training on a set of tasks that could benefit from having shared lower-level features.
- Usually: Amount of data you have for each task is quite similar
- Can train a big enough neural network to do well on all the tasks.
Remind: Multi-task learning is not so often used, except in the case of computer vision / image recognition. In most other fields transfer learning is used more.
End-To-End Deep Learning
Pros:
- Let the data speak
- Less hand-designing of components needed
Cons:
- May need large amount of data
- Excludes potentially useful hand-designed components
Key question: Do we have sufficient data to learn a function of the complexity needed to map x to y
