"Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world." Einstein
Support Vector Machine
SVM is an alternative view for logistic regression. Starting from logistic regression we can derive a good understanding of basic SVM.
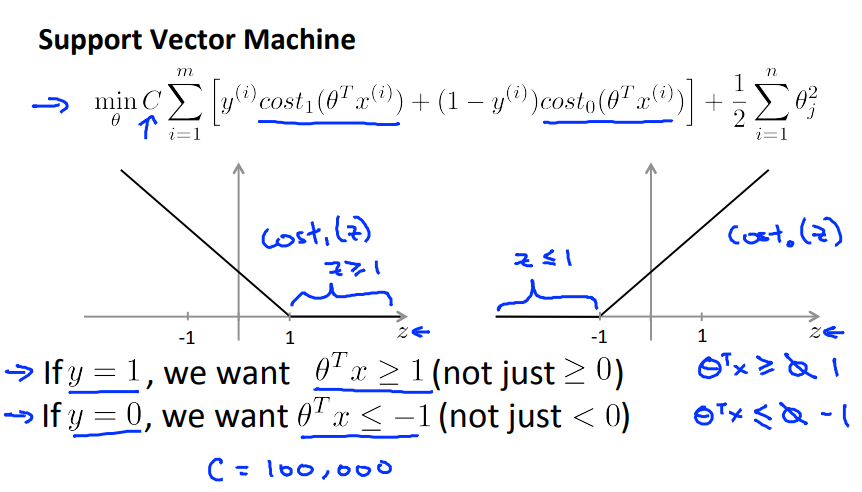
Also helpfull is the concept of large margins or decision boundaries to help understand what SVM’s are doing under the hood.
SVM Decision Boundary
Kernels

###But How To Get Those Landmarks? The training example are exactly the landmarks with the corresponding values (0 or 1) to which category they belong to.
Given example x:
…
In a Gaussian Kernel similarity corresponds to:
All the are grouped for each training example in a feature vector with the first entry .
Hypothesis:
Given , compute features
Predict if
Training:
By solving this minimization problem, we get our parameters for the support vector machine.
Implementation Detail
The last parameter is usually implemented as , while ignoring . This also corresponds to . This is done due to large numbers of features n, to reduce its computation time.
SVM Parameters
.
- Large C: Lower bias, high variance.
- Small C: Higher bias, low variance.
- Large : Features vary more smoothly. Higher bias, lower variance.
- Small : Features vary less smoothly. Lower bias, high variance.
SVM Software Packages
- liblinear
- libsvm
If we use existing SVM’s we have to specify:
- Choice of parameter C
- Choice of kernel (similarity function), eg. no kernel means linear kernel and it predicts if .
In many frameworks we have to define the Kernel function, e.g. in Octave/Matlab And note, that we do perform feature scaling before using the Gaussian kernel.
All valid similarity functions used in kernels have to satisfy the technical condition called Mercer’s Theorem.
Off-The-Shell Kernels
- Polynomial kernel
- String kernel
- Chi-square kernel
- Histogram intersection kernel
Multi-Class Classification
Many SVM packages already have built-in multi-class classification functionalty.
