"I very rarely think in words at all. A thought comes, and I may try to express in words afterwards." Einstein
Anomaly Detection
is distributed Gaussian with mean and variance . Also called the normal distribution.
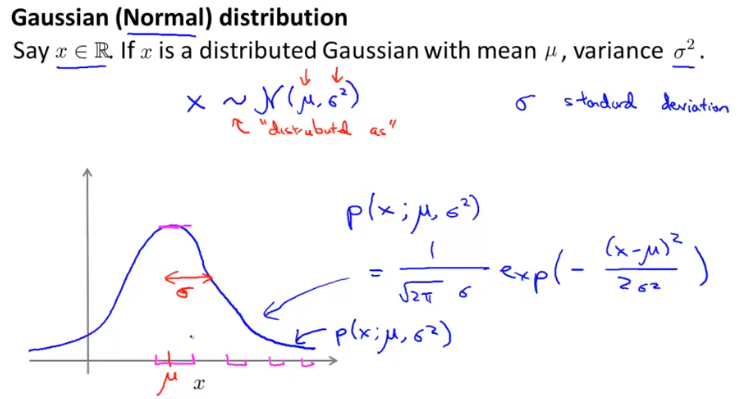
is the with of the Gaussian curve and is where the Gaussian curve is centered.
Parameter Estimation
This is called Maximum Likely-Hood Estimation in statistics.
Density Estimation
By using the Gaussian distribution to estimate the density of our samples.
Detection Algorithm

Developing and Evaluating An Anomaly Detection System
When we develope a learning algorithm (choosing features, etc.), making a decision is much easier if we have a way of evaluating our learning algorithm.
Assume we have some labeled data of anomalous (y = 1) and non-anomalous (y = 0 if normal) examples.
We have a larger number of normal examples and some anomalous examples. We divide them as usual into train, cross-validation and test set.
Algorithm Evaluation
Possible evaluation metrics for a treshold :
- True positive, false positive, false negative, true negative
- Precision/Recall
- Score (tells you the ground truth anomalies given a certain threshold)
We compute precision and recall with:
where
- tp is the number of true positives: the ground truth label says it’s an anomaly and our algorithm correctly classified it as an anomaly.
- fp is the number of false positives: the ground truth label says it’s not an anomaly, but our algorithm incorrectly classified it as an anomaly.
- fn is the number of false negatives: the ground truth label says it’s ananomaly, but our algorithm incorrectly classified it as not being anomalous.
Anomaly Detetion
- Fraud detectino
- Manufacturing (e.g. aircraft engines)
- Monitoring machines in a data center
Supervised Learing
- Email spam classification
- Weather prediction (sunny, rainy, etc.)
- Cancer classification
Choosing What Features to Use
Arrange the data in a Gaussian bell like curve. Use different transformation to make the data more gaussian, e.g. or or .
% show the data as a histogram
hist(x);Error Analysis
We want p(x) to be large for normal examples x and p(x) small for anomalous examples x.
Common Problem
The most common problem to that is, that p(x) is comparable (say, both large) for nomal and anomalous examples. A possible solution to this is trying to come up with more features to distinguish between the normal and the anomalous examples.
Multivariate Gaussian Distribution
We don’t model separately, instead we model all in one go.
Parameters: (covariance matrix).
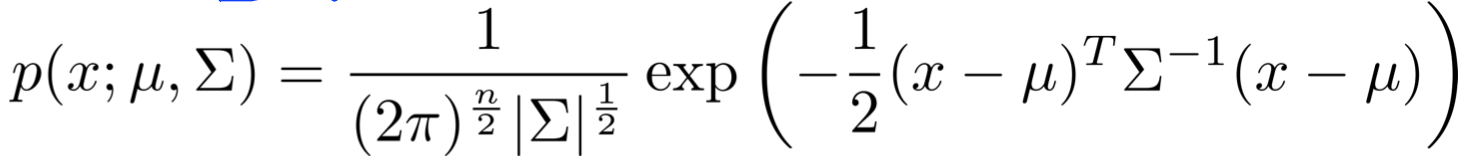
is the determinate and can be computed in Matlab/Octave by
determinate = det(Sigma)Shifting And Distorsion
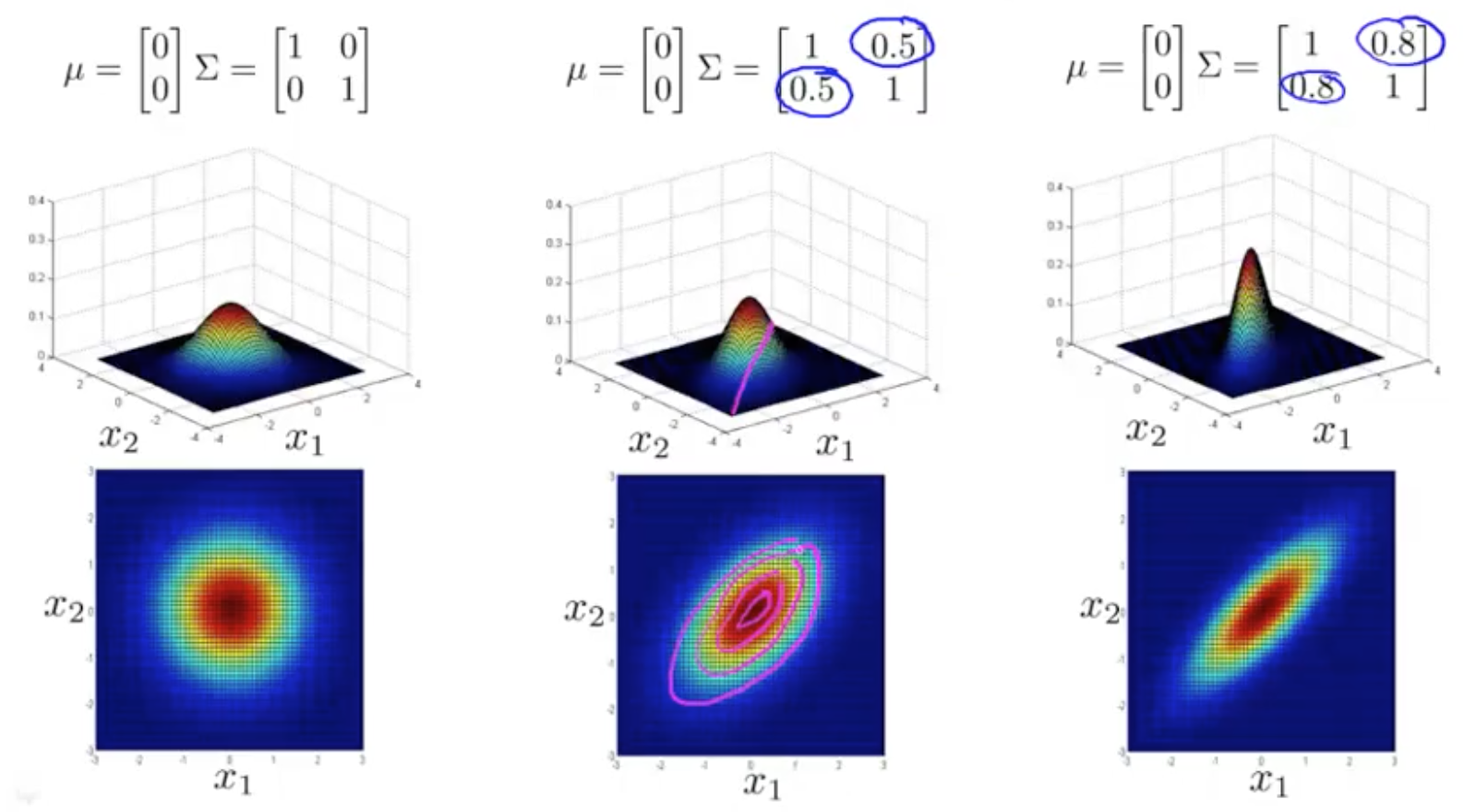
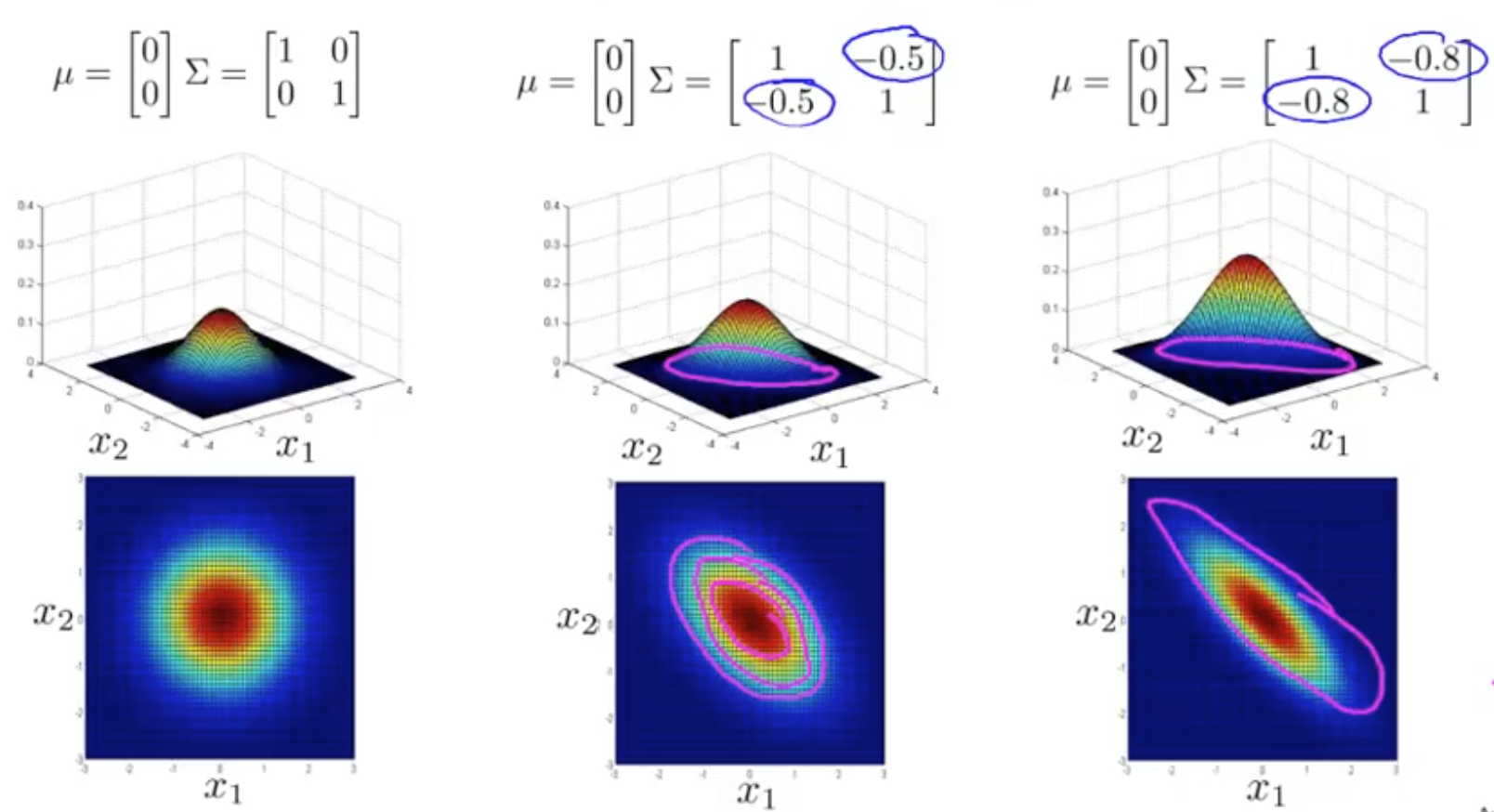
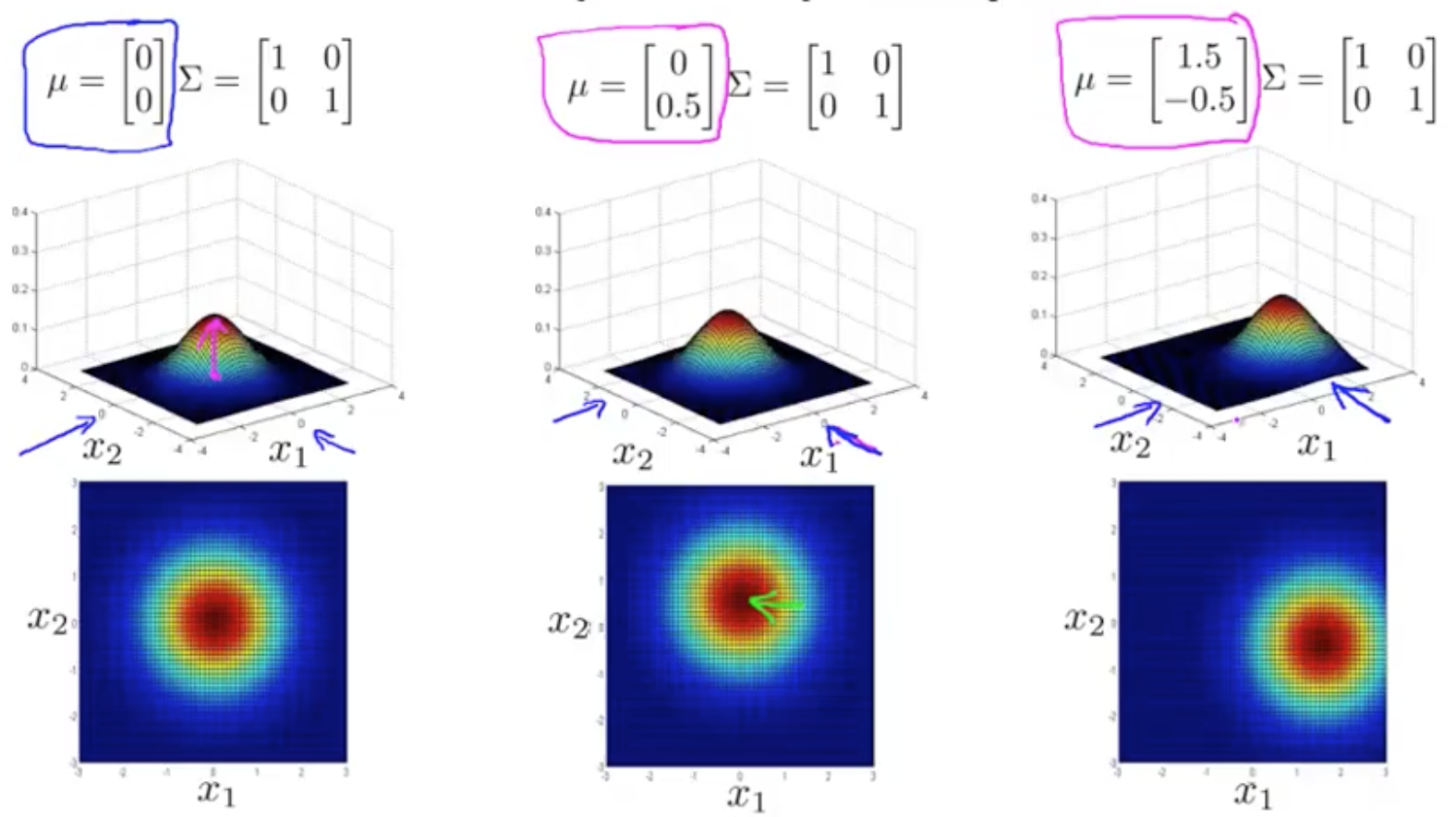
Anomaly Detection With The Multivariate Gaussian
- Fit model p(x) by setting
- Given a new example x, we compute p(x)
And flag an anomaly if .
Original Model
-
Manually create features to cature anomalies where , take unusual combinations of values.
-
Computationally cheaper ( alternatively, scales better to large n).
-
OK even if m (trainings set size) is small
Multivariate Gaussian
-
Automatically captures correlations between features.
-
Computationally more expensive.
-
Must have , or else is non-invertible.
