"Do not worry about your difficulties in Mathematics. I can assure you mine are still greater." Einstein
Mini-batch Gradient Descent
Looking back to Batch Gradient Descent, Vectorization allows us to efficiently compute on m examples. But if m is big it is still very slow because you have to train the complete training set.
Mini-batch Gradient Descent splits up the data samples into baby batches.
Mini-batch t
How It Works
for
Forward-Prop on
Compute Cost
Backprop to compute gradients cost (using ()
Mini-batch Size

Make sure that the mini-batch fits in the CPU/GPU memory (64, 128, 256, 512).
Shuffling
Partition

Exponentially Weighted Averages
While we are averaging over larger data.
is a hyperparameter.
How It Works
This is an exponentially decaying function and this becomes to .
Implementation Notes
Bias Correction in Exponentially Weighted Average
The curve from the above equation starts very low due to the initialization of with 0.
is used for bias correction. But bias correction is not applied very often.
Gradient Descent With Momentum
Used to prevent diverting and/or overshooting gradient descent. The goal is to achieve a specific gradient descent faster in broader elipses and slower in narrower elipses
Average Steps
Physical Description
Look at it as a ball is rolling down a bowl, where and are the velocities, the derivatives the gaining acceleration and the friction. It is easy to imagine how the ball is rolling down.
Hyperparameters
This introduces a new hyperparameter to the existing . Normally start with .
RMSprop
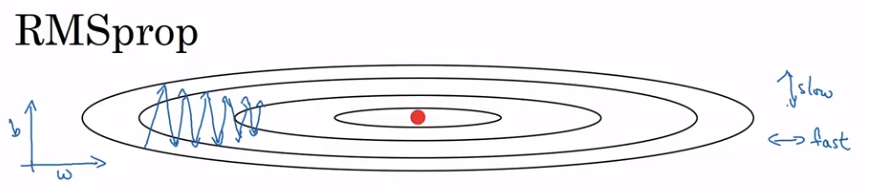
Element-wise squaring of the acceleration.
Adam Optimization Algorithm
Adam := Adaptive Moment Estimation
This is a combination of gradient descent with momentum and RMSprop.
Implementation
- It calculates an exponentially weighted average of past gradients, and stores it in variables (before bias correction) and (with bias correction).
- It calculates an exponentially weighted average of the squares of the past gradients, and stores it in variables and .
- It updates parameters in a direction based on combining information from “1” and “2”.
The update rule is:
where:
- counts the number of steps taken of Adam
- and are hyperparameters that control the two exponentially weighted averages
- is the learning rate
- is a very small number to avoid diving by zero
Hyperparameters Choice
:= needs to be tuned
Learning Rate Decay
One epoch is 1 pass through the data.
Other Methods
Problem of Local Optima
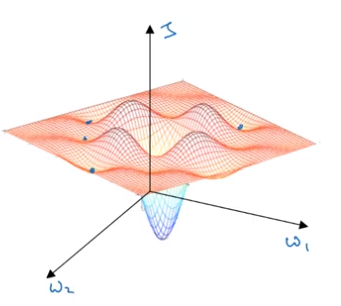
Other possiblities are sattel point, meaning it is shaped as a horse sattel and therefore zero points are no always local or global minimas.
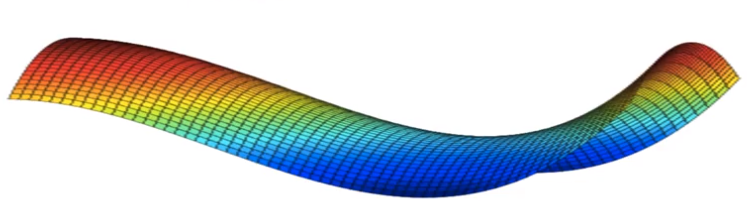
Platforms can make learning very slow and then ADAM and likewise can really help to speed up the training.
Tuning Process
- The following hyperparameters can be tuned: , , #layers, #hidden units, learning rate decay, mini-batch size.
- It is better to try random values instead of using a parameter grid.
- We should use a coarse to fine sampling scheme
Appropriate Scale To Pick Hyperparameters
- Use a logarthmic scale to chose from for the learning rate .
Possible implementation in Python:
1
2
3
4
# Values between 0.0001 and 1
def scaleLearningRate:
r = -4 * np.random.rand()
learning_rate = np.power(10, r)
In pratice, hyperparameters can be tuned by means of Pandas or Caviar. It’s good pratice to re-evaluate the parameters every month or so.
During development a model can be babysit one model. Another approach would be to train many models in parallel. The first babysitting approach is callend Panda and the second is the Caviar approach.
This mainly depends on the resources we have at hand and the size of data to be processed.
There is a another approach which not always fits the problem we are facing. It is possible to normalize the activations in a network.
Batch Normalization
Batch normalization allows to train deeper neural networks, makes the hyperparameter search more easier and the network much more robust. Usually it is used with mini-batches. Batch norm are used per first mini-batch, then second and so on.
Idea
Normalized inputs speed up learning. The question is can we normalize so as to train , faster? This is what Batch Normalization is doing.
Implementation
Given some intermediate values in my NN
where
- and are learnable hyperparameters of the model
- Use instead of
for t = 1 ... numMiniBatches
Compute forward prop on X_T
In each hidden layer, use N to replace z_l with zTilde_l
Use back prop to compute dW_l, db_l, dBeta_l, dGamma_l
Update the parameters
W_l = W - alpha * dW_l
beta_l = beta_l - alpha * dBeta_l
gamma_l = gamma_l - alpha * dGamma_l Learning On Shifting Input Distribution
A trained NN can not be easilier applied to a shifted version of training data. This is called covariance shift.
Image an deeper NN where the later hidden layers would perfectly fit the problem, but the first few hidden layer not, we would have to shift the NN to fit the new problem. This can be done by Batch Norm.
A second effect coming from batch norm:
- Each mini-batch is scaled by the mean/veriance omputed on just that mini-batch
- This adds some noise to the values within that minibatch. So similar to dropout, it adds some noise to each hidden layer’s activation
- This has a slight regularization effect.
Batch Norm At Test Time
The first two equation cannot be computed during test time, therefore we estimate and using exponentially weigthed average (across mini-batches). Most frameworks offers an interface to create and .
Softmax Layer
The softmax layer function has the special ability to take a vector as input instead of a single value. Otherwise it is similar to the activation function.
The names come from the hard max approach where a multiclass classification results are mapped to a vector, eg. for being a result of the first class of 4:
Softmax is normalizing the classification values instead of the above mentioned hard coded vector.
Examples
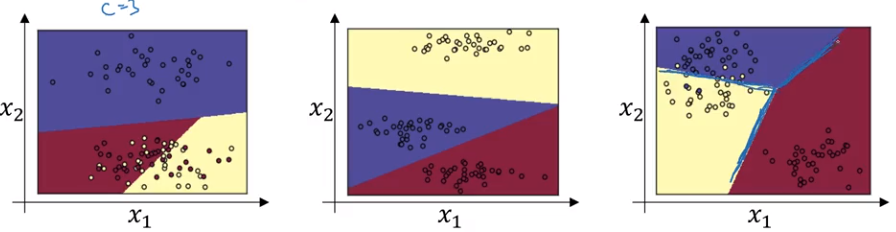
Separate the date into for example three different classes, where the softmax layer can be seen as a generaization of the logistic regression.
Training A Softmax Classifier
Softmax regression generalizes logistic regression to C classes. If , softmax reduces to logistic regression. We would have to compute only one output.
Lost Function
Backward Propagation
