"Do not worry about your difficulties in Mathematics. I can assure you mine are still greater." Einstein
What to keep in mind regarding Calculus for Back Propagation.
Introduction
To compute derivates in Neural Networks a Computation Graph can help. It contains both a forward and a back propagation.
Back propagation contains Calculus, or more specific we have to take different Derivatives. Look at it as a computation from right to left.
Chain Rule
Wording
:= layer 2, example i, neuron j
Formulas for Forward and Back Propagation
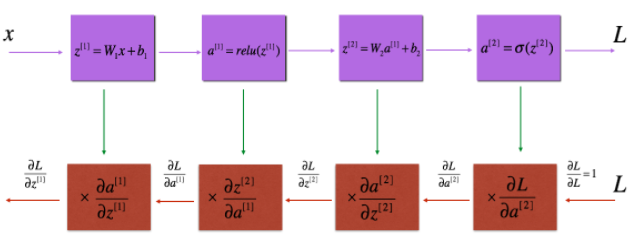
Forward Propagation
Estimation function
Sigmoid function
Node
Loss (error) function
Logistic Regression Cost Function
Vectorized implementation
Forward Propagation with Dropout
Create matrix with the same dimension as the corresponding activation matrix and initialize it randomly. Then set all values to 0 or 1 regarding the keep probability. Then multiply the activation matrix with the dropout matrix and divide the remaining values by the keep probability.
Backward Propagation
Suppose you have already calculated the derivative , then you want to get , and .
where
Summary of gradient descent
Vectorized implementation example
The derivative of cost with respect to
Calculation Problem with Zero Matrix
Initialize weights with a 2x2 zero matrix is a problem. The computed a’s will be the same. And the dW rows will also be the same. This is independent how many cycles are be computed.
Random Initialization
We should initialize the parameters randomly. The parameters are := n of input layer, := n of hidden layer and := n of output layer
Where does the constant 0.01 comes from? We prefer to use very small initialization values. This means we will not start at the flat parts of the curve.
Xavier or He Initialization
Xavier initialization uses the factor instead of 0.01. And He et al. proposed the slightly adapted factor .
General Gradient Descent Rule
Update Rule For Each Parameter
L2 Regularization
The standard way to avoid overfitting is called L2 regularization. It consits of appropriately modifying your cost function.
to:
The first term is named cross-entropy cost and the second term L2 regularization cost.
Observations
- The value of is a hyperparameter that you can tune using a dev set.
- L2 regularization makes your decision boundary smoother. If is too large, it is also possible to oversmooth, resulting in a model with high bias.
Implementation Details
To calculate use
1
np.sum(np.square(W1))
Backpropagation With Regularization
For each node we have to add teh regularization term’s gradient .
Backpropagation with Dropout
Multiply the derivative with the corresponding droupout matrix cached in the forward propagation. Finally divide the remaining values in the activation matrix by the keep probablity.
